Method
Architecture
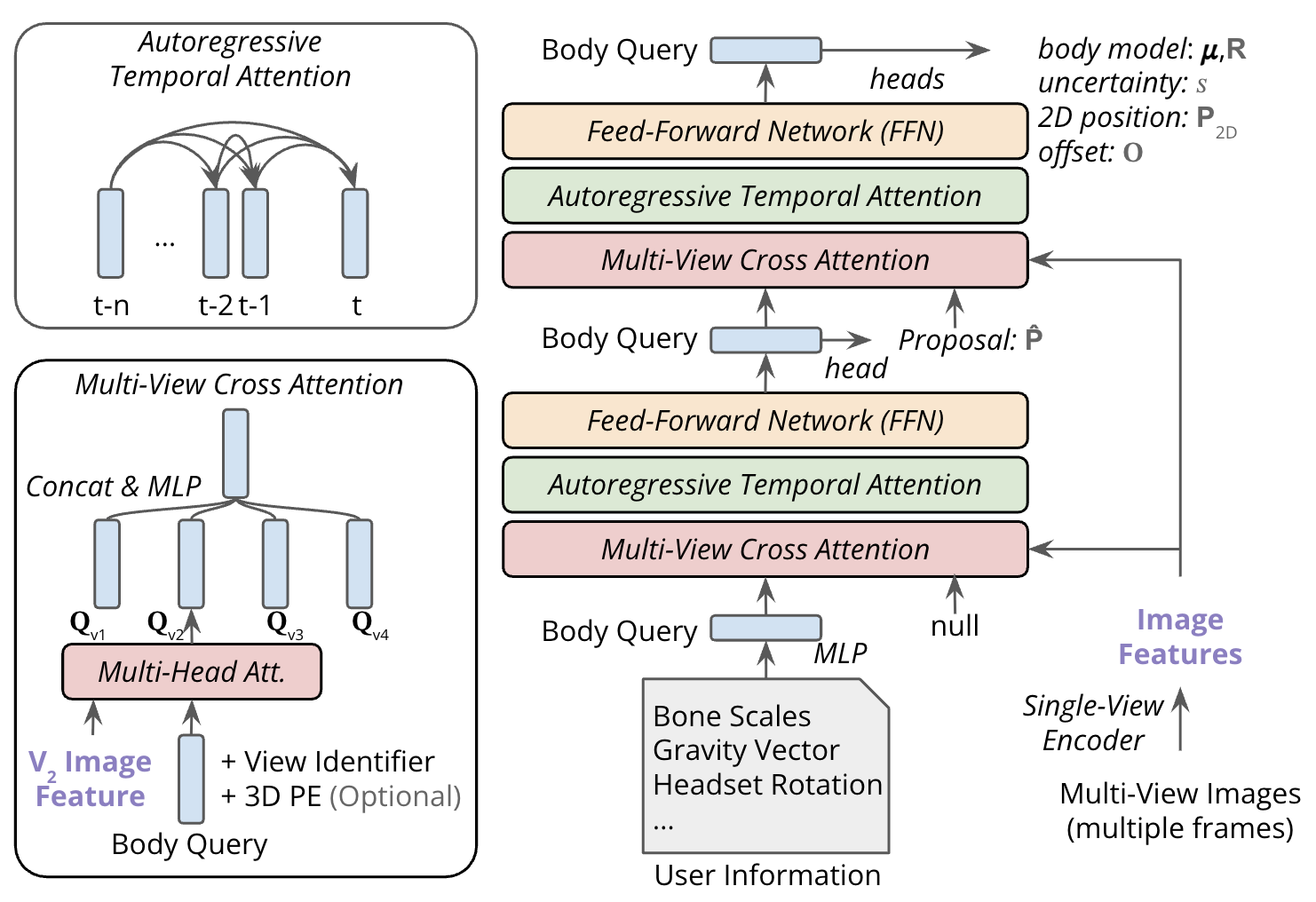
EgoPoseFormer v2 is a fully differentiable, end-to-end transformer architecture. Unlike its predecessor that uses separate learnable queries for each joint, EPFv2 uses a single holistic query conditioned on pose-dependent metadata (user identity and headset pose) to represent the entire body state. This makes computation independent of the body representation, improving efficiency and flexibility.
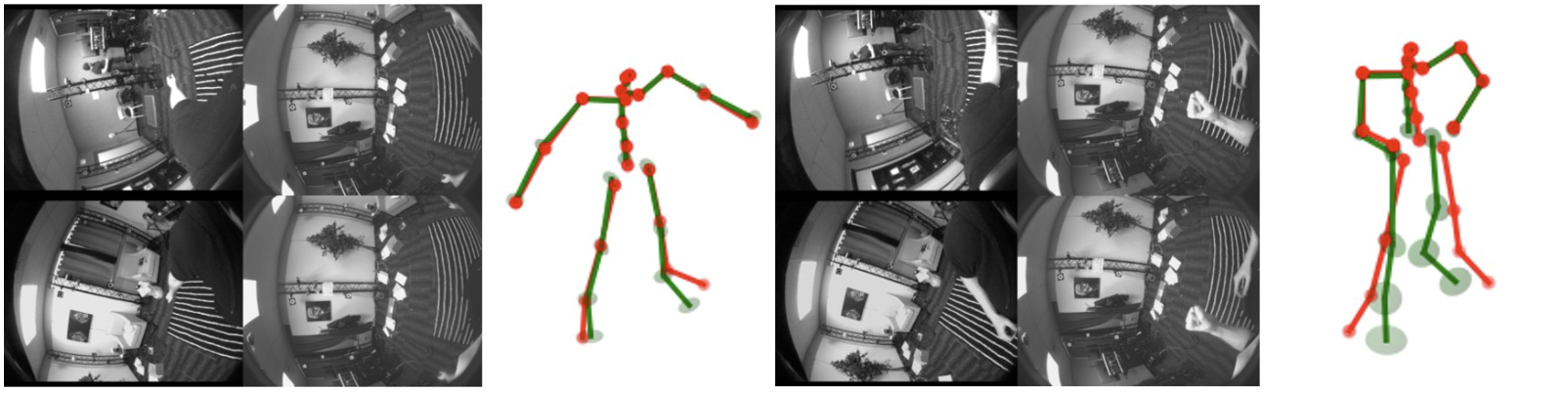
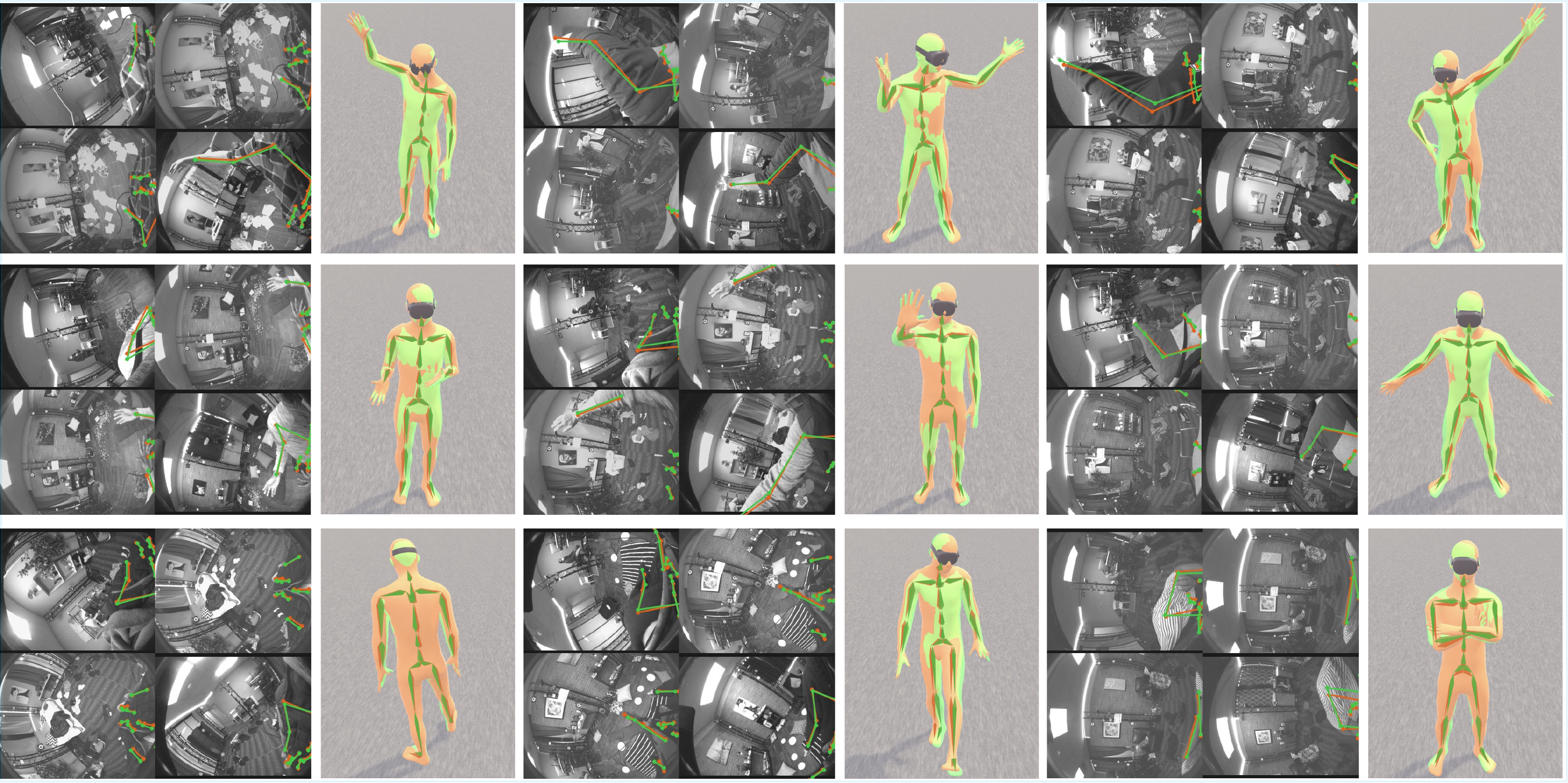
The model stacks two architecturally identical transformer decoder blocks with full gradient flow. The first decoder predicts an initial 3D pose from temporal multi-view features. The second refines the estimation by projecting coarse 3D keypoints onto image planes and using the 2D positions as spatial conditioning for conditioned multi-view cross-attention. Coupled with causal temporal attention, EPFv2 produces accurate, temporally-consistent motion even for invisible body parts.
Auto-Labeling System
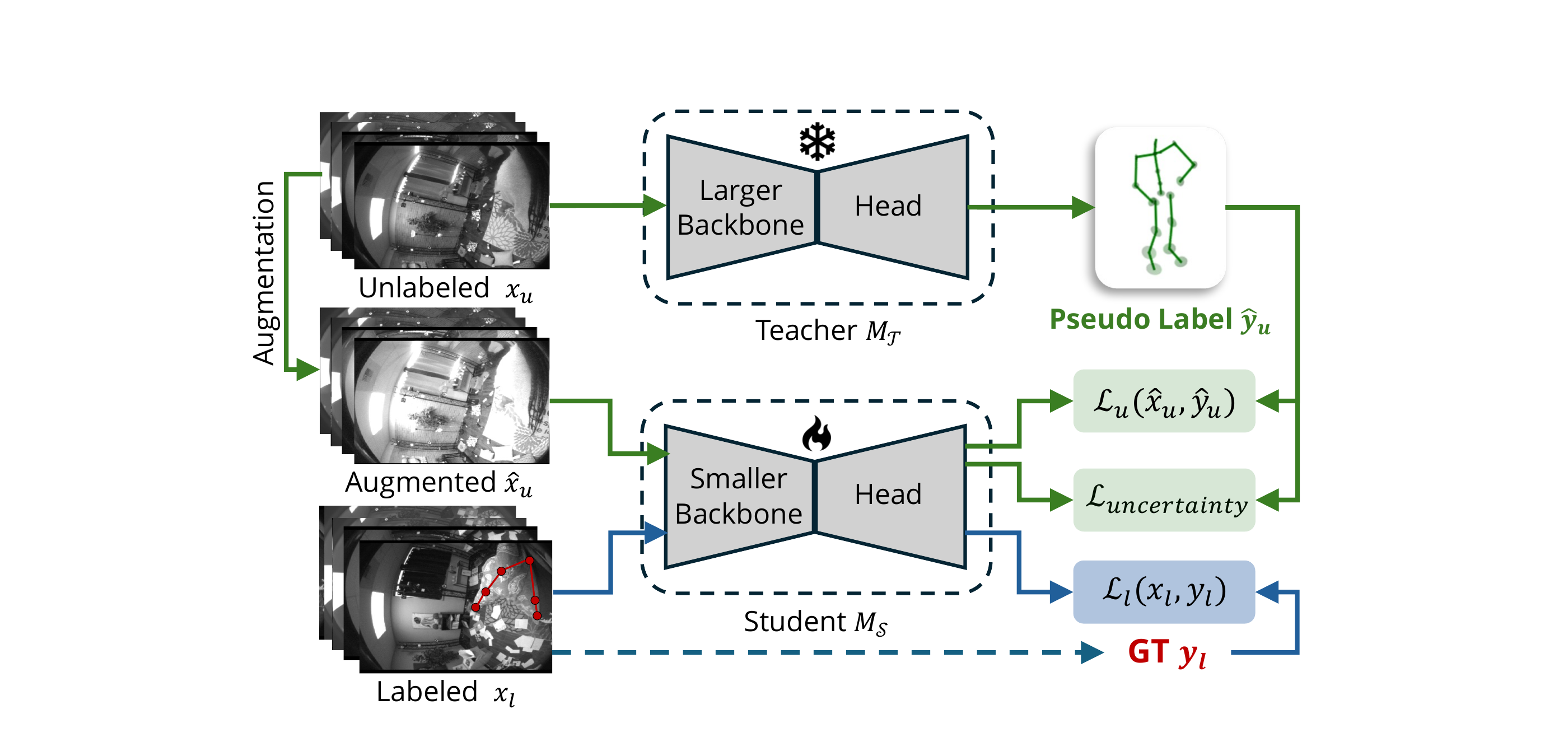
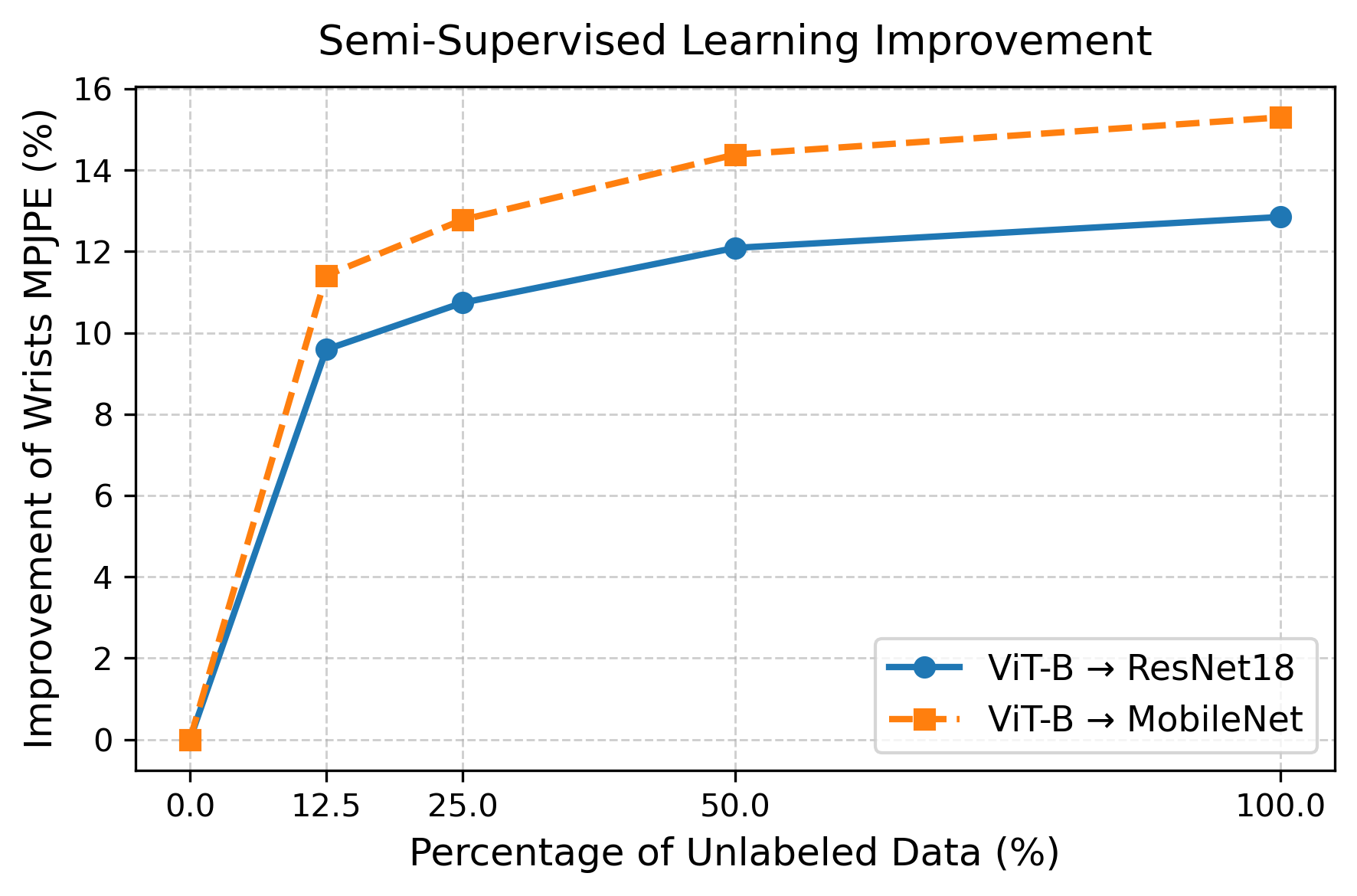
Collecting large-scale, labeled egocentric motion data is costly. EPFv2 adopts a scalable semi-supervised learning pipeline that leverages large collections of unlabeled egocentric videos. A high-quality teacher model is trained on a small labeled subset and used to generate pseudo-labels for a large pool of unlabeled data. The student is then trained jointly on labeled and pseudo-labeled samples using an uncertainty-guided distillation loss, enabling it to recognize and down-weight unreliable pseudo-labels.